
Künstliche Intelligenz in Laborumgebungen wird oft entweder über- oder unterschätzt. Auf der einen Seite steht die Angst vor einer undurchsichtigen „Black Box", auf der anderen die Erwartung vollautonomer Systeme, die komplexe Laborprozesse eigenständig steuern. Die Realität – wie so oft – liegt irgendwo dazwischen.
Aus technischer Sicht ist KI im Labor kein magisches System, sondern eine hochspezialisierte Software-Schicht. Sie verbindet bestehende Labor-IT, Geräte, Datenströme und regulatorische Rahmenbedingungen auf strukturierte und kontrollierte Weise. Plattformen wie LabThunder illustrieren dieses Prinzip in der Praxis – nicht durch Ersatz etablierter Systeme, sondern durch Steigerung des Informationswerts bereits vorhandener Daten.
Dieser Artikel untersucht, wie Labordigitalisierung durch KI technisch funktioniert, welche Kernmechanismen ihr zugrunde liegen und warum der echte Mehrwert nicht im Modell selbst liegt, sondern im kontextuellen Verständnis.

1. Labor-KI ist domänenspezifisch – nicht generisch
Ein grundlegender Fehler in vielen KI-Diskussionen ist die Annahme, dass ein allgemeines Sprachmodell automatisch für Laboranwendungen geeignet ist. In der Praxis ist das Gegenteil der Fall.
Labormanagement Software mit integrierter KI muss in der Lage sein:
- Technische und wissenschaftliche Terminologie präzise zu "verstehen"
- Normative und regulatorische Verweise korrekt zu interpretieren
- Messlogik, Einheiten, Toleranzen und Geräteverhalten zu respektieren
- Regulatorische Implikationen jeder Empfehlung zu berücksichtigen
Die entscheidende Unterscheidung
Das zugrunde liegende Sprachmodell ist nicht die Intelligenz selbst – es stellt lediglich die Interaktionsebene bereit. Die eigentliche Domänenintelligenz entsteht aus strukturierten Wissensräumen, Metadaten, Beziehungen und Zugriffskontrollmechanismen.
Technisch bedeutet dies, dass Labor-KI nicht allein auf Freitext-Interpretation angewiesen ist. Stattdessen operiert sie auf domänenspezifischen semantischen Strukturen, die Folgendes repräsentieren:
- Geräteklassen (z.B. HPLC, GC-MS, ICP-MS) für optimiertes Equipment Management
- Einheiten, Grenzwerte und normative Umrechnungen
- Abkürzungen und laborspezifische Nomenklatur
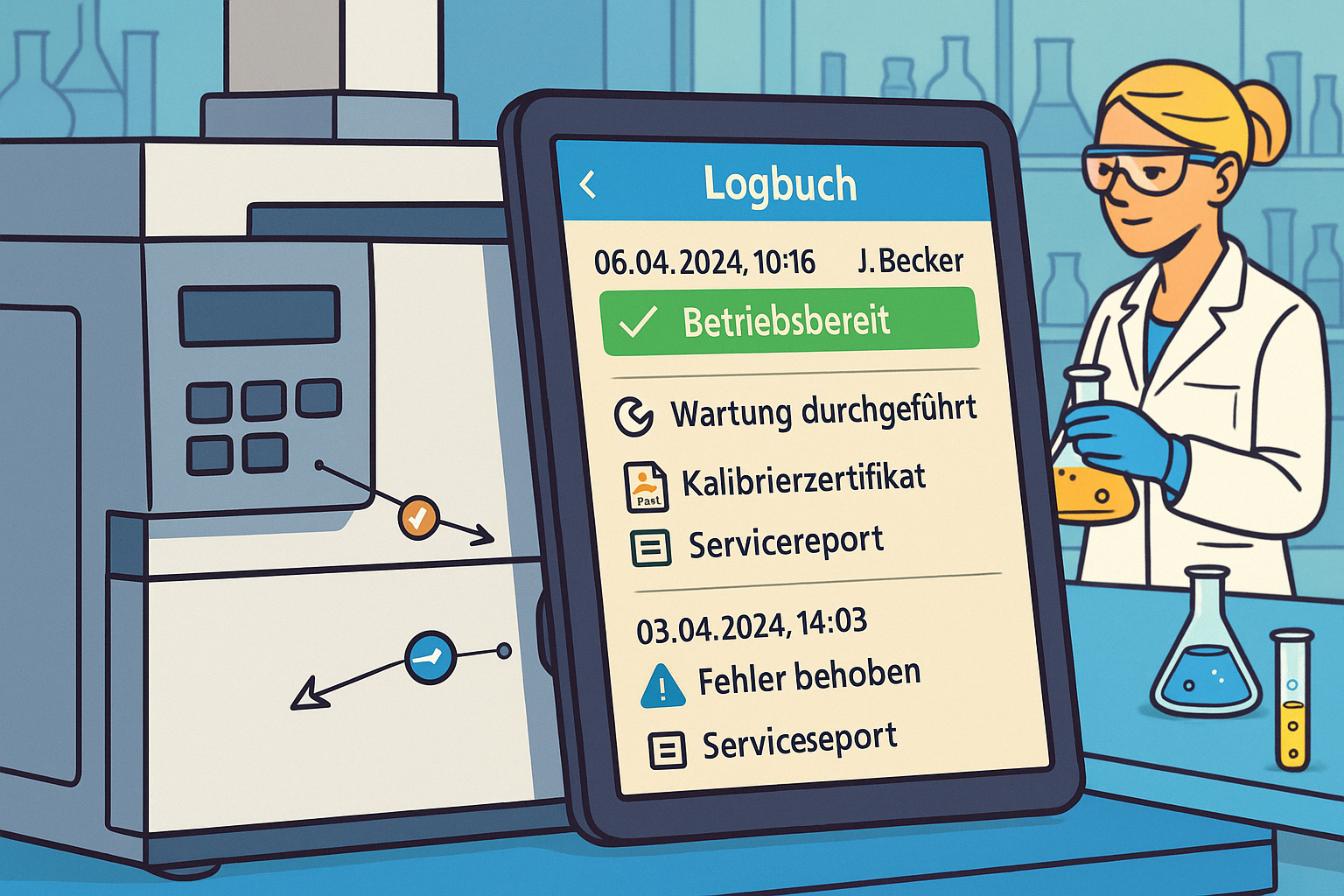
- Beziehungen zwischen Systemen, SOPs, Logs, Wartungsereignissen, Kalibrierungen und Dokumentation
In Systemen wie LabThunder wird die Fachsprache daher nicht nur erkannt, sondern strukturell innerhalb kontrollierter Wissensdomänen interpretiert.
2. Informationsverknüpfung: Der eigentliche Leistungssprung in der Labordigitalisierung
Die größten Produktivitätsgewinne durch KI im Labor stammen nicht von „intelligenteren Antworten", sondern von schnellerer und vollständigerer Kontextbildung.
Klassische Laborrealität
Ein erfahrener Labormitarbeiter untersucht Probleme typischerweise durch:
- Suche in System- und Geräte-Logs
- Durchsicht von Wartungs- und Serviceberichten
- Vergleich von SOP-Versionen
- Analyse von Kalibrier- und Qualifizierungshistorien
- Manuelle Recherche in Handbüchern und Dokumentationen
Dieser Ansatz ist technisch korrekt – aber langsam, fragmentiert und stark von individueller Erfahrung abhängig.
KI-basierte Kontext-Aggregation im Equipment Management
Labormanagement Software mit KI-Funktionen agiert als Kontext-Aggregator. Sie konsolidiert Informationen über heterogene Quellen hinweg durch Verknüpfung von:
- Zeitlichen Korrelationen (was hat sich kürzlich geändert?)
- Dokument- und Versionsbeziehungen
- Gerätezuständen und Betriebshistorie
- Wartungs-, Kalibrier- und Vorfalls-Zeitlinien
Diese Konsolidierung wird nicht durch einfache Volltextsuche erreicht, sondern durch strukturierte Metadaten, Zeitlinien und explizite Objektbeziehungen. Geräte, Logs, Dokumente und Serviceaufzeichnungen werden als verbundene Informationsobjekte behandelt, nicht als isolierte Dateien.
Wichtig: Diese Verknüpfung erfordert nicht zwangsläufig eine dedizierte Graph-Datenbank. Relationale Datenmodelle sind bereits in der Lage, robuste kontextuelle Argumentation zu unterstützen, wenn sie mit wohldefinierten Beziehungen, Metadaten und temporalen Strukturen angereichert und entsprechend konzipiert sind.

Der eigentliche Durchbruch liegt nicht in der Intelligenz selbst, sondern in der Fähigkeit, durch tief verknüpfte Daten unmittelbar Kontext zu bilden.
3. Kontextbasierte Argumentation statt regelbasierter Logik
Ein verbreitetes Missverständnis ist, dass Labor-KI primär auf starren If-Else-Regelwerken operiert.
Beispiel: „Warum ist meine HPLC-Basislinie instabil?"
Ein rein regelbasiertes System würde vordefinierte Checklisten abarbeiten. Eine kontextfähige KI im Labor evaluiert stattdessen:
- Historische Baseline-Trends
- Kürzliche Wartungs- oder Konfigurationsänderungen
- Relevante Troubleshooting-Abschnitte in Handbüchern und SOPs
- Vergleichbare Vorfälle im gleichen Laborkontext
Technisch konstruiert das System einen Hypothesenraum, ordnet mögliche Ursachen nach Wahrscheinlichkeit und präsentiert testbare Erklärungen – keine absoluten Schlussfolgerungen.
Der entscheidende Punkt
KI lernt nicht autonom im Sinne eigenständiger Entscheidungen. Sie evaluiert bekannte Muster innerhalb eines strikt definierten Daten- und Regelraums.
Diese Unterscheidung ist in regulierten Umgebungen essentiell:
KI entscheidet nicht – sie unterstützt Entscheidungen auf transparente und nachprüfbare Weise.
5. Mandantenfähigkeit, Datensicherheit und DSGVO-konforme KI-Nutzung
In Multi-Organisationsumgebungen ist Mandantenfähigkeit nicht optional – sie ist grundlegend.
Technische Isolation für effektive Labordigitalisierung
Jede Organisation operiert innerhalb eines strikt isolierten Datenkontexts. Dokumente, Logs, Metadaten und Analyseergebnisse werden einem einzelnen Mandanten zugeordnet und ausschließlich innerhalb dieser Grenze verarbeitet.
Die KI-Schicht greift nicht auf einen globalen Datenpool zu. Sie operiert strikt innerhalb des autorisierten Scopes und der Rollenberechtigungen des Nutzers und spiegelt damit wider, worauf der Nutzer auch manuell zugreifen könnte.
DSGVO-konforme KI-Operationen im Equipment Management
Aus datenschutzrechtlicher Sicht sind moderne Labor-KI-Systeme so konzipiert, dass:
- Sensible Daten maskiert oder von Modell-Prompts ausgeschlossen werden können
- Personenbezogene Informationen minimiert oder abstrahiert werden
- Zugriff auf vertrauliche Daten auf der Abruf-Ebene durchgesetzt wird, nicht auf Modellebene
Das Sprachmodell selbst behält keine kundenspezifischen Daten. Kontext wird transient und nur für die Dauer der Interaktion bereitgestellt, was die Einhaltung von DSGVO-Prinzipien wie Datenminimierung und Zweckbindung gewährleistet.
6. KI als Wissensschicht über bestehender Infrastruktur
Aus CTO-Perspektive ist ein Prinzip entscheidend:
KI ersetzt keine LIMS-, ELN- oder QMS-Systeme.
Stattdessen fungiert sie als intelligente Wissens- und Interaktionsschicht, die:
- Daten liest, aber validierte Aufzeichnungen nicht unkontrolliert modifiziert
- Informationen analysiert, aber keine autonomen Entscheidungen trifft
- Workflows beschleunigt, ohne Verantwortung zu übernehmen
Dieses nicht-invasive Design macht KI kompatibel mit:
- Bestehenden IT-Landschaften
- Legacy-Laborsystemen
- Validierten und regulierten Prozessen
In der Praxis ergänzen moderne Labor-KI-Systeme LIMS-Umgebungen durch verbesserte Zugänglichkeit, Interpretation und kontextuelle Verknüpfung – ohne in validierte Kernfunktionen einzugreifen.
7. Der echte Mehrwert: Wissensdemokratisierung im Labor durch Labordigitalisierung
Mit der Zeit leistet KI im Labor mehr als nur Prozessoptimierung – sie formt Organisationsstrukturen neu:
- Expertenwissen wird kontextuell zugänglich
- Einarbeitungszeiten werden reduziert
- Fehlerquellen werden früher identifiziert
- Entscheidungen basieren auf vollständigeren Informationen
Dies ist kein abstrakter Vorteil, sondern ein direktes Ergebnis besser vernetzter Daten.
Praktische Auswirkungen
Laborleitung steht vor einer doppelten Herausforderung: datengetriebenes, KI-unterstütztes Arbeiten zu ermöglichen und gleichzeitig strikte regulatorische Compliance aufrechtzuerhalten. Moderne Plattformen für Labormanagement Software müssen daher:
- Explorative und flexible Workflows unterstützen
- Strukturierte Compliance dort durchsetzen, wo erforderlich
- Nahtlose Übergänge zwischen beiden Modi ermöglichen
- Vollständige Audit-Trails aufrechterhalten
Fazit aus CTO-Perspektive: Die Zukunft der Labordigitalisierung
KI im Labor ist weder Science-Fiction noch Marketing-Gimmick. Sie ist eine technisch anspruchsvolle Integrationsschicht für effektives Equipment- und Labormanagement, die:
- Technische Laborsprache interpretieren kann
- Zuverlässigen Kontext aufbaut
- Informationen intelligent verknüpft
- Entscheidungen vorbereitet, statt sie zu ersetzen
Der eigentliche Durchbruch kommt nicht von immer größeren Modellen, sondern von tieferem Domänenverständnis und diszipliniertem Systemdesign.
Die entscheidende Frage für Labore im Kontext der Labordigitalisierung ist daher nicht:
„Ist KI sicher?"
Sondern vielmehr:
„Können wir es uns leisten, weiterhin ohne kontextuelle Intelligenz zu arbeiten?"
Häufige Fragen zur Anwendung von KI im Labor
Wie unterscheidet sich Labor-KI von allgemeinen KI-Systemen wie ChatGPT?
Labor-KI ist domänenspezifisch konzipiert und versteht die technische Fachsprache, normative Anforderungen und regulatorische Rahmenbedingungen der Laborumgebung. Während allgemeine Sprachmodelle die Interaktionsebene bereitstellen, entsteht die eigentliche Intelligenz aus strukturierten Wissensräumen mit Geräteklassen, Messlogik, SOPs und Equipment Management-Daten. Die KI operiert auf semantischen Strukturen, nicht nur auf Freitext-Interpretation.
Ersetzt KI bestehende LIMS- oder ELN-Systeme im Rahmen der Labordigitalisierung?
Nein. KI fungiert als intelligente Wissens- und Interaktionsschicht über bestehender Infrastruktur. Sie liest und analysiert Daten aus LIMS, ELN und QMS-Systemen, modifiziert aber keine validierten Aufzeichnungen unkontrolliert. Dieses nicht-invasive Design macht Labor-KI kompatibel mit Legacy-Systemen und validierten Prozessen, während es die Zugänglichkeit und kontextuelle Verknüpfung von Informationen verbessert.
Wie wird die DSGVO-Konformität bei KI-gestützter Labormanagement Software sichergestellt?
Moderne Labor-KI-Systeme arbeiten mit strikter Mandantenfähigkeit und Datenisolation. Jede Organisation operiert in einem isolierten Datenkontext, und die KI greift nur auf autorisierte Daten zu. Sensible Informationen können maskiert werden, personenbezogene Daten werden minimiert, und das Sprachmodell selbst speichert keine kundenspezifischen Daten. Der Kontext wird nur transient für die Dauer der Interaktion bereitgestellt.
Wo liegt der größte Mehrwert von KI in der Labordigitalisierung?
Der Hauptvorteil liegt nicht in "intelligenteren Antworten", sondern in der schnellen Kontextbildung durch Informationsverknüpfung. Die KI aggregiert Daten aus Geräte-Logs, Wartungsberichten, SOPs, Kalibrierungshistorien und Dokumentationen in Sekunden – ein Prozess, der manuell Stunden dauern würde. Dies beschleunigt Troubleshooting, reduziert Einarbeitungszeiten und demokratisiert Expertenwissen im gesamten Labor.

LabThunder:
✅ Compliant nach ISO 17025, GMP/GLP und ISO 15189
✅ Digitale Logbücher statt Zettelchaos
✅ Thunder AI - zentrale Intelligenz bei Fehlern & Fragen
✅ Smarte & Predictive Maintenance verhindert Ausfälle
✅ Mehr Unabhängigkeit von externem Service
✅ bis zu 50 % weniger Serviceeinsätze
✅ easy to use - keine IT nötig
Kontaktieren Sie uns noch heute für einen kostenfreie Demo:




















.jpg)
.jpg)

